Introduction
Deep Neural Networks (DNNs) have become essential in various applications, from computer vision to natural language processing. However, deploying these models efficiently at scale presents significant challenges. This blog post explores an innovative solution developed by us at UC Santa Cruz that implements dynamic batching in RAY to optimize GPU utilization while maintaining performance requirements.
Understanding the Problem
Why is this Important?
Modern GPUs are incredibly powerful machines:
- They offer 100+ TFLOPS (trillion floating-point operations per second)
- They’re more cost-effective than traditional CPU solutions
- They’re essential for fast model execution
However, there’s a catch:
- GPUs are expensive, high-capacity devices
- Their cost benefits only materialize when they maintain high utilization
- Most individual models or applications can’t fully utilize a GPU’s capacity
Current Limitations in RAY
RAY currently uses a static batching approach with two key parameters:
batch_wait_timeout_s # How long to wait for forming a batch
max_batch_size # Maximum size of the batch
This static approach has several drawbacks:
- Can’t adapt to changing workload patterns
- Leads to GPU underutilization during low-traffic periods
- May cause SLO violations during traffic spikes
- Results in inefficient resource allocation across multiple models
The Solution: Dynamic Batching
What is Batching?
Before diving into the solution, let’s understand what batching means in this context:
- Definition: Grouping multiple inputs or requests into a single batch for simultaneous processing
- Benefits:
- Improves GPU utilization
- Increases requests processed per second
- Reduces overhead from frequent kernel launches
The Squishy Bin Packing Approach
The team innovatively formulated the problem using a concept called “squishy bin packing”:
- Bins = GPUs
- Each GPU represents a container (bin)
- Bin size = GPU memory capacity
- Sections = DNN Models
- Each model takes up space in the bin
- Section size = Memory needed for the current batch size
- Squishy Nature
- Sections can grow or shrink
- Size changes based on batch size adjustments
- Allows dynamic resource allocation
Dynamic Batching:
When we can vary the batch size, the sections in the bin packing problem now become squishy!
Inspiration: NEXUS Scheduling Algorithm
NEXUS is cluster engine which introduces an approximation algorithm for the squishy bin packing problem.
- The algorithm creates a list of DNN models with corresponding batch sizes to execute for each GPU
- The models are then executed in a round robin fashion
Algorithm Implementation

The algorithm follows this structure:
SQUISHYBINPACKING(Sessions)
1: nodes, residue_loads ← SCHEDULESATURATE(Sessions)
2: nodes ← nodes ⊕ SCHEDULERESIDULE(residue_loads)
3: return nodes
SCHEDULESATURATE(Sessions)
4: nodes, residue_loads ← [], []
5: for Si = (Mki, Li, Ri) in Sessions do
6: Bi ← argmaxb(2ℓki(b) ≤ Li)
7: Ti ← Bi/ℓki(Bi)
8: let Ri = n · Ti + ri
9: nodes ← nodes ⊕ n GPU nodes for Mki with batch Bi
10: residue_loads ← residue_loads ⊕(Mki, Li, ri)
11: return nodes, residue_loads
System Architecture
The system consists of four main layers working together. The following diagram shows the complete architecture:
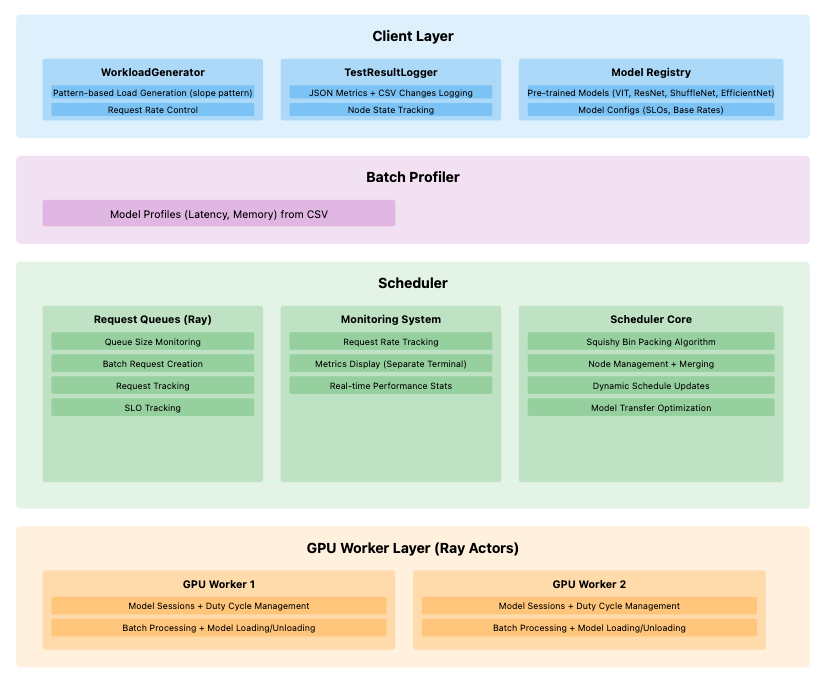
Let’s examine each layer in detail:
1. Client Layer
The topmost layer handling incoming requests and workload management:
- WorkloadGenerator
- Creates pattern-based load generation
- Controls request rates
- Simulates real-world scenarios
- TestResultLogger
- Logs JSON metrics and CSV changes
- Tracks node states
- Maintains performance history
- Model Registry
- Manages pre-trained models (ViT, ResNet, ShuffleNet)
- Stores model configurations
- Handles SLOs and base rates
2. Batch Profiler
A dedicated layer for performance monitoring:
- Maintains model profiles with:
- Latency measurements
- Memory utilization patterns
- Performance metrics
3. Scheduler
The brain of the system, consisting of three main components:
a. Request Queues (Ray)
- Monitors queue sizes
- Creates batch requests
- Tracks individual requests
- Monitors SLO compliance
b. Monitoring System
- Tracks request rates in real-time
- Displays metrics on a separate terminal
- Maintains real-time performance statistics
c. Scheduler Core
- Implements the squishy bin packing algorithm
- Manages nodes and merging operations
- Handles dynamic schedule updates
- Optimizes model transfers between GPUs
4. GPU Worker Layer
The execution layer using Ray actors:
- Handles model sessions
- Manages duty cycles
- Processes batches
- Handles model loading/unloading
Implementation Details
Request Flow and Processing
The following diagram illustrates how requests flow through the system:
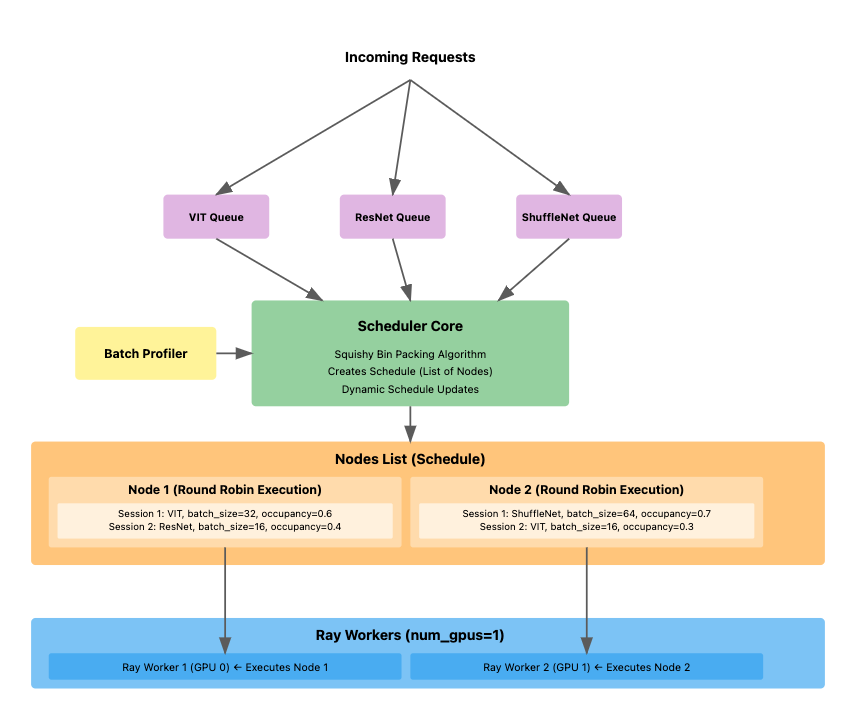
The NEXUS Algorithm
The system implements a two-phase scheduling algorithm:
def squishy_bin_pack(models, gpus):
# Phase 1: Schedule Saturate
# Efficiently pack models into minimum GPUs
nodes, residue = schedule_saturate(models)
# Phase 2: Schedule Residue
# Handle remaining workload
final_nodes = schedule_residue(nodes, residue)
return final_nodes
Example Output
Here’s what the node schedule looks like in practice:
Node gpu type: A6000, Node gpu memory: 11GB
Node duty cycle: 12.0ms
Node sessions: 1
session number 1 has occupancy: 100.0%
Model name: vit, SLO: 25ms, request rate: 3830.0, batch size: 47
Node gpu type: A6000, Node gpu memory: 11GB
Node duty cycle: 19.0ms
Node sessions: 2
session number 1 has occupancy: 28.0%
Model name: vit, SLO: 25ms, request rate: 1170.0, batch size: 22
session number 2 has occupancy: 47.0%
Model name: resnet, SLO: 50ms, request rate: 1000.0, batch size: 19
Experimental Results
The team conducted extensive experiments to validate their approach:
Scenario 1: Single Model Analysis
Setup:
- Model: ResNet-50
- Request Rate: Linear increase from 0 to 40 requests/second over 40 seconds
- SLO Requirement: 2000ms
Results:
- Batch size automatically increased with request rate
- Maintained 100% SLO compliance
- Zero request drops during the experiment
- Efficient GPU utilization throughout the test
Scenario 2: Multi-Model Deployment
Setup:
- Models: ResNet-50, ViT, ShuffleNet
- Request Rate: All models ramping from 0 to 40 req/s over 40 seconds
- Different SLO requirements for each model
Observations:
- Initial Phase:
- All three models placed on single GPU
- Low batch sizes due to low request rates
- Mid-Load Phase:
- ViT required dedicated GPU access as load increased
- ResNet automatically migrated to second GPU
- Maintained average GPU utilization of 89%
- Full-Load Phase:
- Optimal distribution across both GPUs
- High utilization while maintaining SLOs
- Effective duty cycle management
Future Work
The team identified several areas for improvement:
1. Performance Optimization
- Replace Python implementation with low-level language
- Implement shared memory mechanisms
- Optimize queue management
- Reduce scheduling overhead
2. Feature Enhancement
- Support for chained DNN models
- Deeper integration with Ray’s internal scheduling
- Advanced monitoring capabilities
- Enhanced profiling features
3. Scalability Improvements
- Support for larger GPU clusters
- More sophisticated model migration strategies
- Enhanced load balancing mechanisms
Conclusion
This implementation of dynamic batching in Ray represents a significant advancement in DNN serving systems. By addressing the limitations of static batching and implementing an intelligent scheduling system, the team has demonstrated a practical solution for maintaining high GPU utilization while meeting service-level objectives.
The project shows particular promise in:
- Handling varying workloads
- Automatically adjusting batch sizes
- Redistributing models across GPUs
- Maintaining optimal performance
As deep learning continues to grow in importance, such efficient serving systems will become increasingly crucial for production environments.
References
- NEXUS - Haichen Shen, et al. (2019). “Nexus: A GPU Cluster Engine for Accelerating DNN-Based Video Analysis.” SOSP ‘19